Wrappare il sito della mia università con Python
Un piccolo progetto fatto nel tempo libero per potere velocizzare l'accesso ai documenti per studiare
Il problema
Qualche mese fa ero fuori casa, connesso al mio hotspot mobile e stavo studiando per un esame. Nel mentre che dal portale per il materiale didattico della mia università switchavo i file degli appunti trovavo estremamente snervante il fatto che ogni singola pagina, nonostante cache e rete ci metteva numerosi secondi a caricarsi. Posso capire siti come youtube o reddit, ma un sito dal quale prendere documenti per studiare quanti file in background deve caricare oltre alla pagina principale?! Tornato a casa, prendo burpsuite e mi metto a dare un’occhiata a quali richieste avvengono:
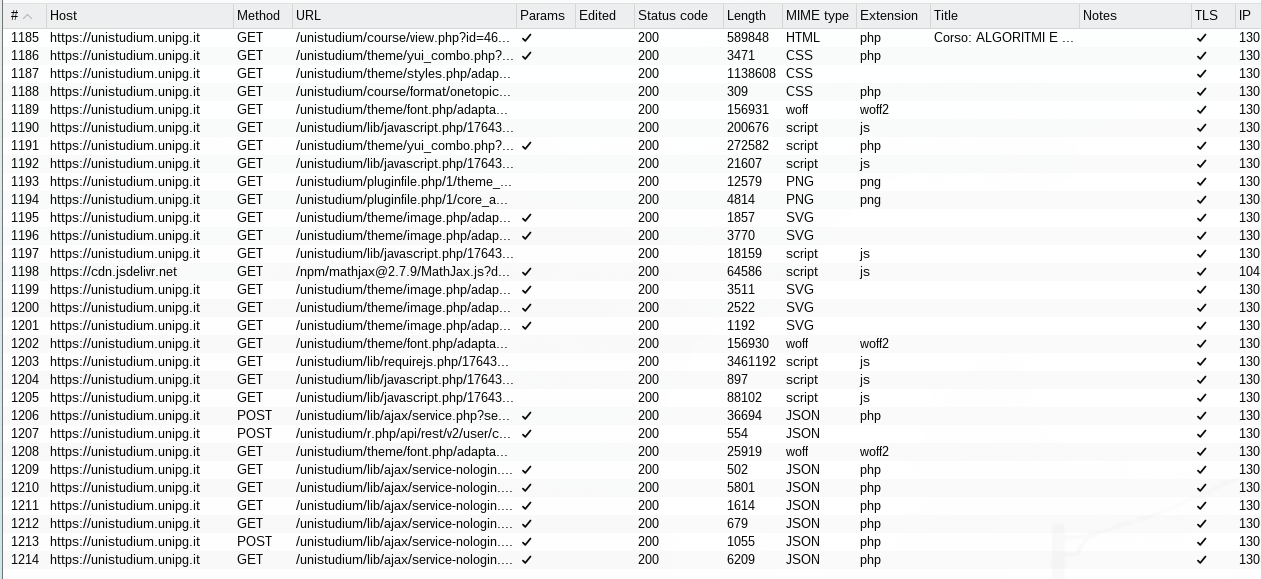
Solo nella prima pagina dopo aver fatto il login abbiamo 17 richieste. Una POST iniziale fatta da me e tutte le altre sono interne, per il servizio di login ma soprattutto per numerosi file di dimensioni notevoli che appesantiscono la rete. Una volta dentro il portale, quando accediamo ad un corso le richieste effettuate sono le seguenti:
29 richieste. Per carità, un totale di quasi 50 richieste sono poche se consideriamo che un accesso alla home di youtube senza account sono circa 200. Ma comunuqe, mi rompeva le scatole che per vedere i documenti dell’università, non avendo una rete super veloce, una pagina in media mi ci mette dai 2 ai 4 secondi a caricare con picchi fino a 7 secondi.
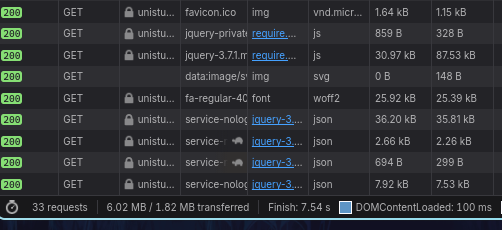
Quindi invece di finire di studiare ho deciso di prendere il mio peggior nemico (python) e di scrivere un wrapper da terminale con lo scopo di velocizzare l’accesso su reti per gente che come me non ha la fibra o vive in mezzo al nulla.
Il progetto
L’idea iniziale del progetto è semplice:
- da python faccio una richiesta get al sito con requests
- dentro la request metto i cookie di sessione
- profit Ovviamente ci sono già tantissimi problemi. Per iniziare, unistudium utilizza l’autenticazione SAML (Security Assertion Markup Language). Questo accesso non è facile da replicare, visto che utilizza un identity provider per l’autenticazione e, in breve, avrei dovuto scrivere tutto il processo di redirect intreno ad unistudium. Di conseguenza non potevo direttamente recuperare un cookie di sessione da mettere nella request. Per superare questo limite ho dovuto implementare playwright. Playwright è una libreria nata per il testing end-to-end di web app, un pò eccessiva come soluzione, ma finchè funziona ci accontentiamo.
Iniziamo con la definizione dei browser da utilizzare e la rispettiva verifica di quello presente nel sistema dell’utente
browsers = [
("Firefox", playwright.firefox, None),
("Opera", playwright.chromium, "/usr/bin/opera"),
("Brave", playwright.chromium, "/usr/bin/brave"),
("Chromium", playwright.chromium, None), #chromium va in fondo perchè qua si odia tutto ciò che è della google
("WebKit", playwright.webkit, None),
]
context = None
for name, engine, path in browsers:
try:
launch_args = {
"user_data_dir": "/tmp/playwright-user-data",
"headless": False,
}
if path:
launch_args["executable_path"] = path
context = engine.launch_persistent_context(**launch_args)
print(f"✓ Browser utilizzato: {name}")
break
except Exception as e:
print(f"✗ {name} non disponibile: {e}")
continu
if context is None:
raise RuntimeError("Nessun browser disponibile per Playwright!")Ora, dal browser in playwright, noi faremo un normale login da unistudium, in modo da non dover replicare tutto il sistema di login SAML. Ci rimane a questo punto da recuperare il cookie e possiamo liberamente navigare
page = context.new_page()
print("Effettua il login su UniStudium...")
page.goto(self.LOGIN_URL)
timeout = 120 # secondi
start = time.time(
moodle_cookie = None
cookies = context.cookies()
moodle_cookie = next(
(c for c in cookies if c["name"] == self.COOKIE_NAME),
None,
)
current_moodle_cookie = None
while time.time() - start < timeout:
cookies = context.cookies()
current_moodle_cookie = next(
(c for c in cookies if c["name"] == self.COOKIE_NAME),
None,
)
if moodle_cookie != current_moodle_cookie:
print(current_moodle_cookie)
break
time.sleep(0.2)
if not current_moodle_cookie:
raise TimeoutError("Cookie di login non trovato entro il timeout")In questo pezzo di codice possiamo vedere alcune cose interessanti.
Innanzitutto con page.goto apriamo il browser di playwright selezionato in context.
In seguito settiamo il cookie di moodle con il primo cookie che troviamo nella pagina con quel nome.
Questo perchè nella prima pagina di login è già presente un cookie con quel nome, probabilmente con lo scopo di autenticare una prima connessione con il servizio SAML. Quindi prendiamo quel cookie che non ci appartiene, lo salviamo e una volta che si avvia il processo di auth, aspettiamo che nel nostro context ci sia un cookie nuovo con quel nome e lo salviamo.
La parte più difficile è stata superata.
Per rendere le pagina visualizzabili dall’utente ci basterà utilizzare la libreria Beautifulsoup e nel particolare il modulo bs4.
Analizzando il codice sorgente delle varie pagine unistudium vediamo che ci sono vari elementi HTML con classi che ci facilitano il parsing della pagina web richiesta.
Nel nostro metodo fetch_courses prendiamo il risultato della get, lo parsiamo, selezioniamo il valore del tag <a> e del suo relativo href da tutti i corsi, che saranno generati dinamicamente così
<h3 class="coursename">
<a href="...">Corso</a>
</h3>Il codice è questo
def fetch_courses(self) -> List[Tuple[str, str]]:
"""Recupera la lista dei corsi disponibili"""
response = requests.get(self.BASE_URL, cookies=self.get_cookies_dict())
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
courses = []
for h3 in soup.select("h3.coursename a"):
name = h3.get_text(strip=True)
link = h3["href"]
courses.append((name, link))
return coursesQuesto ci ritornerà una lista con nome del corso e relativo link.
Quando l’utente da terminale andrà a selezionare il corso, faremo la richiesta get con il relativo corso selezionato, dalla quale ricaveremo tutte le attività del corso.
Il concetto del parsing con beautifulsoup è uguale. Nel codice sorgente vediamo che le sezioni saranno sempre padri h3 con figli a tutto dentro una list con classe section
response = requests.get(course_url, cookies=self.get_cookies_dict())
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
sections = []
for section in soup.select("li.section.course-section"):
section_name_tag = section.select_one("h3.sectionname a")
if not section_name_tag:
continue
section_name = section_name_tag.get_text(strip=True)
activities = []
for item in section.select("li.activity"):
link_tag = item.select_one("a")
if not link_tag or not link_tag.get("href"):
continue
title = link_tag.get_text(strip=True)
url = link_tag["href"]
activities.append({"title": title, "url": url})
if activities: # Aggiungi solo sezioni con attività
sections.append({"name": section_name, "activities": activities})
return sectionsOra dobbiamo rendere possibile il download dei documenti. Per fare questo, andiamo a fare una richiesta get iin stream all’url della risorsa richiesta, determiniamo il filename remoto (con relativa sanitize e controllo di duplicati) e mettiamo una piccola progressbar grazie alla libreria tqdm. Questa libreria itererà per tutta la total size del file richiesto e stamperà il progresso del download del file.
def download_file(self, url: str, filename: str = None) -> bool:
"""Scarica un file dall'URL specificato"""
try:
print(f"\n📥 Download da: {url}")
response = requests.get(url, cookies=self.get_cookies_dict(), stream=True)
response.raise_for_status()
# Determina il nome del file
if not filename:
content_disposition = response.headers.get("Content-Disposition", "")
if "filename=" in content_disposition:
filename = content_disposition.split("filename=")[1].strip().strip('"').strip("'")
else:
filename = url.split("/")[-1].split("?")[0] or "download"
filename = self.sanitize_filename(filename)
filepath = self.download_dir / filename
# Gestisci file con stesso nome
counter = 1
original_stem = filepath.stem
while filepath.exists():
filepath = self.download_dir / f"{original_stem}_{counter}{filepath.suffix}"
counter += 1
# Scarica con progress bar
total_size = int(response.headers.get('content-length', 0))
with open(filepath, "wb") as file:
if total_size:
with tqdm(total=total_size, unit='B', unit_scale=True, desc=filename) as pbar:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
file.write(chunk)
pbar.update(len(chunk))
else:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
file.write(chunk)
print(f"✓ Salvato in: {filepath}")
return True
except Exception as e:
print(f"❌ Errore durante il download: {e}")
return FalseQuesti sono i punti critici fondamentali del progetto, tutto il resto sono semplici richieste get di navigazione, stati del programma e contorlli di sicurezza.
Conclusione
Dopo tutta questa pantomima però, abbiamo effettivamente riscontrato dei miglioramenti nei tempi delle richieste? Analizziamo la prima richiesta del login per entrare nella home:
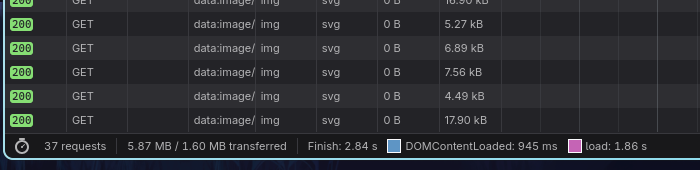
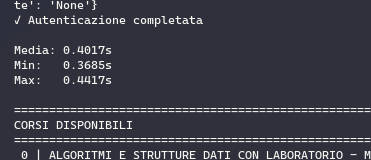
Nel programma da terminale abbiamo un tempo medio (per 10 esecuzioni di richieste) di 0.4 secondi con minima di 0.3 e massima 0.4 (arrotondati). In una navigazione normale il tempo è di oltre 2.5 secondi con ben 37 richieste fatte.
Questo progetto non cambierà assolutamente niente e probabilmente io stesso userò comunque unistudium online, ma è stato un esperimento divertente. Mi ha permesso di giocare un pò con python e di capire quanto oggi giorno è importante essere in grado di fare dei siti che non sovraccarichino la rete con file enormi che finiscono per rallentare l’esperienza dell’utente.